Reducing AWS S3 Storage Costs with Bubble Trees
No, there are not actually bubbles in the trees

Will Carhart
Will Carhart

Note
This post will be talking about Amazon Web Services (AWS) Simple Storage Solution (S3). If you're not familiar with this technology, here is a good primer.
Understanding S3 pricing, and why things get expensive
For most of the companies I've worked for, storage accounted for one of the largest chunks of cloud infrastructure costs. From logging, database storage, artifact repostories, and more, storing data for any modern web application with a sizeable user base will exceed most cloud providers' free tiers. For example, let's take a look at AWS S3 pricing for S3 Standard, which is general purpose storage for any type of data and typically used for frequently accessed data.
| Usage | Cost |
|---|---|
| First 50 TB/month | $0.023 per GB |
| Next 450 TB/month | $0.022 per GB |
| Over 500 TB/month | $0.021 per GB |
23¢/GB/month may seem like a small price to pay. For a 1TB of data, that comes out to $23/month.
Let's use Facebook as an example. As of writing this article, there are approximately 2.375 billion MAU and over 250 billion pictures on Facebook (MAU means monthly active users in reference to a company's user base). Let's estimate the the average user has been on Facebook for about 5 years. This means that the average Facebook user uploads about 21 pictures per year, which Facebook compresses down to a maximum of 100KB per picture. In reality, Facebook likely uses a combination of storage solutions that are much cheaper than AWS S3, but let's assume for estimation sake that storage costs them 23¢/GB/month, just like us. This means that our upper bound cost estimate for Facebook to store the average user's photos is 0.05796¢/year. Seems like a near-zero cost...so why do we care?
Working with expensive amounts of data in S3
Let's think of some storage cases where the storage amount is a little greater. One of the most storage-heavy software applications is DNA sequencing and processing genomic data. Illumina, which is the world's leader in DNA sequencers, can produce close to 800 GB of data per execution of one of their high-end sequencers! If a massive lab has 50 sequencers running everyday for a month (incredibly unlikely, but proving a point), they would produce 1.2 Petabytes of data on a monthly basis. In AWS, that's over $27,000 every month! For reference, that's about one one-millionth the size of the internet in 2013, generated every month. Is this a realistic example? Absolutely not. However, it does show us that when working with massive amounts of data, it's important to be cost-conscious.
One way to do cut cloud storage costs is to set an expiry date for all of your objects, which states that each object will be deleted x days after it was uploaded. However, this poses another problem. Let's run with the Illumina example. If there are hundreds of scientists uploading data every day, how do we alert each individual scientist of when their data is about to be deleted? In order to prevent data loss, we should notify data owners prior to data deletion, which will give them time to move the data or extend the expiry date.
How could we implement a solution to achieve this? Let's write out a few basic requirements of our solution:
- S3 is an object-store, not a regular file system! This means that there are no folders or directories within a bucket, only objects. We can mimic folders by prefixing filenames with a pathnames.
- We need to notify data owners well before their data expires that it will be deleted. For example, if I have a file that will be deleted in two months, I should get a notification at least one month prior to the deletion date.
- We need this process to be reproducible and automated, so it happens at a regular interval and doesn’t take away precious time from us (developers) and scientists (data owners at Illumina, or any other company with massive amounts of data).
- Continuous S3 API calls can get expensive. We want our solution to be as cheap as possible.
How will we accomplish sending out these notifications to data owners?
- We will define a data structure to minimize the number of notifications while still being transparent about which data is expiring and when.
- We will use a simple architecture of various AWS services to deploy our notification service.
Constructing a new data structure: the Bubble Tree
Let's come up with a data structure to store our data. We need:
- A way to store key-value pairs, where the key is the name of the object and the value is its expiry date.
- A hierarchical structure, like a file system of paths.
- A way to minimize the amount of key-value pairs the structure holds.
First, let's consider a trie.
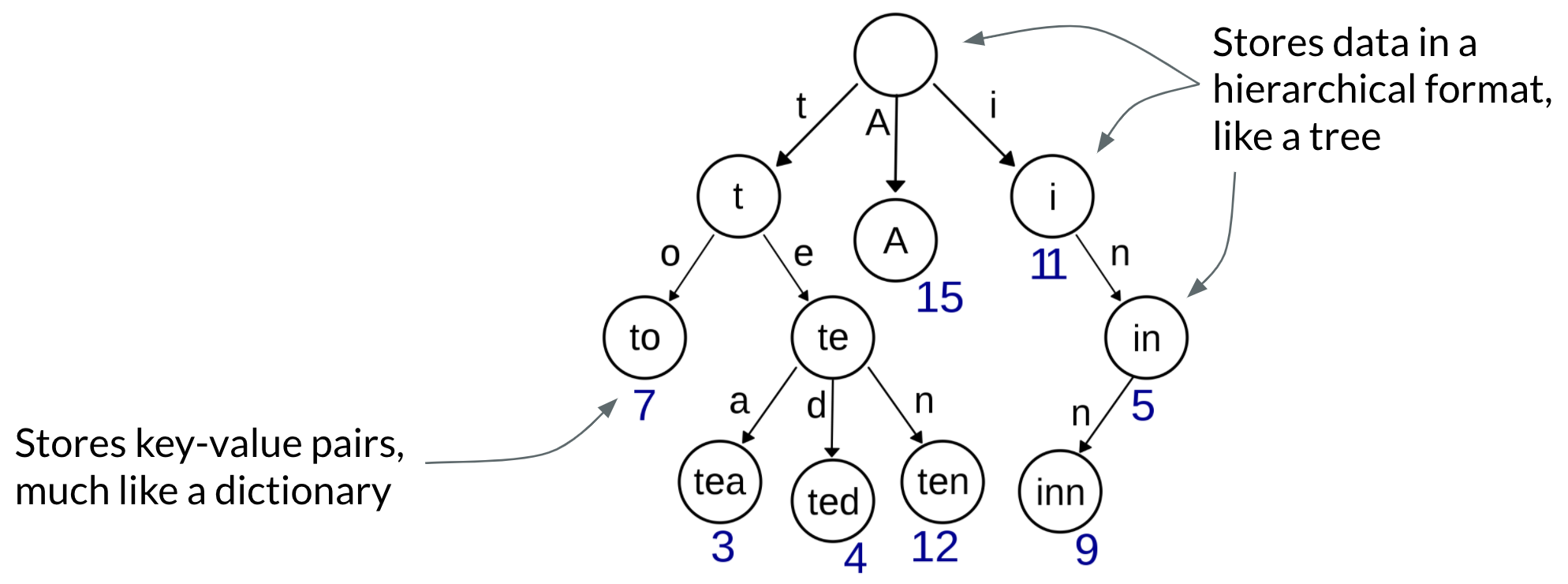
This is a great start. What’s good about a standard trie for our use case? One, it stores key-value pairs, and two, it's hierarchical (great fit for our S3 bucket prefixes). Conversely, what’s not as great about a standard trie for our use case? Well, it's not as minimal. If two children, or leaves, of a node contain the same value, they are both stored.
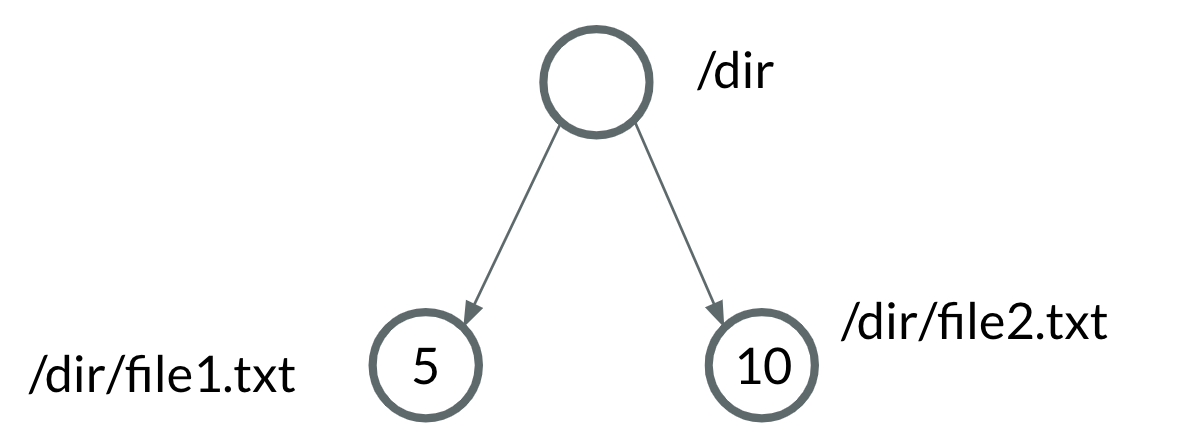
For example, consider the key-value pairs {'/dir/file1.txt': 5, '/dir/file2.txt': 10}. This would result in the following trie.
However, consider a trie with asymmetrical data, such as with the key-value pairs {'/dir/file1.txt': 5, '/dir/file2.txt': 5}. This would result in a trie with three nodes, even though both the leaf nodes have the same value.
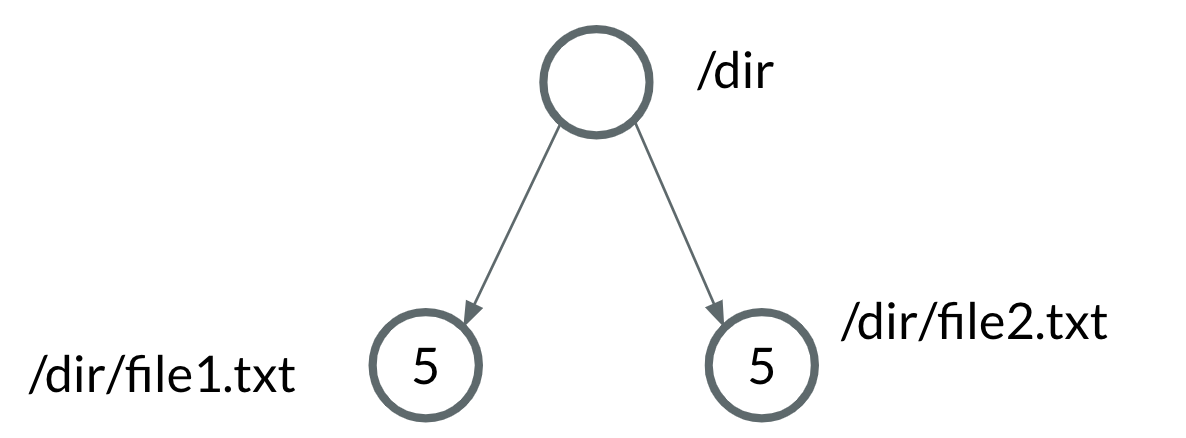
In our case, a simpler representation the data would be {'/dir': 5}, because we know that all of the contents of dir have the value 5.
Let's create a new kind of tree data structure, which we'll call the bubble tree. A bubble tree will be very similar to a trie, but with the following condition: we say that the value of a node bubbles up to its parent if the value of the node is equivalent to the values of all of its siblings.
That sounds complicated in writing, but it's easier to visualize. Check out this simple animation of values bubbling up in a bubble tree.
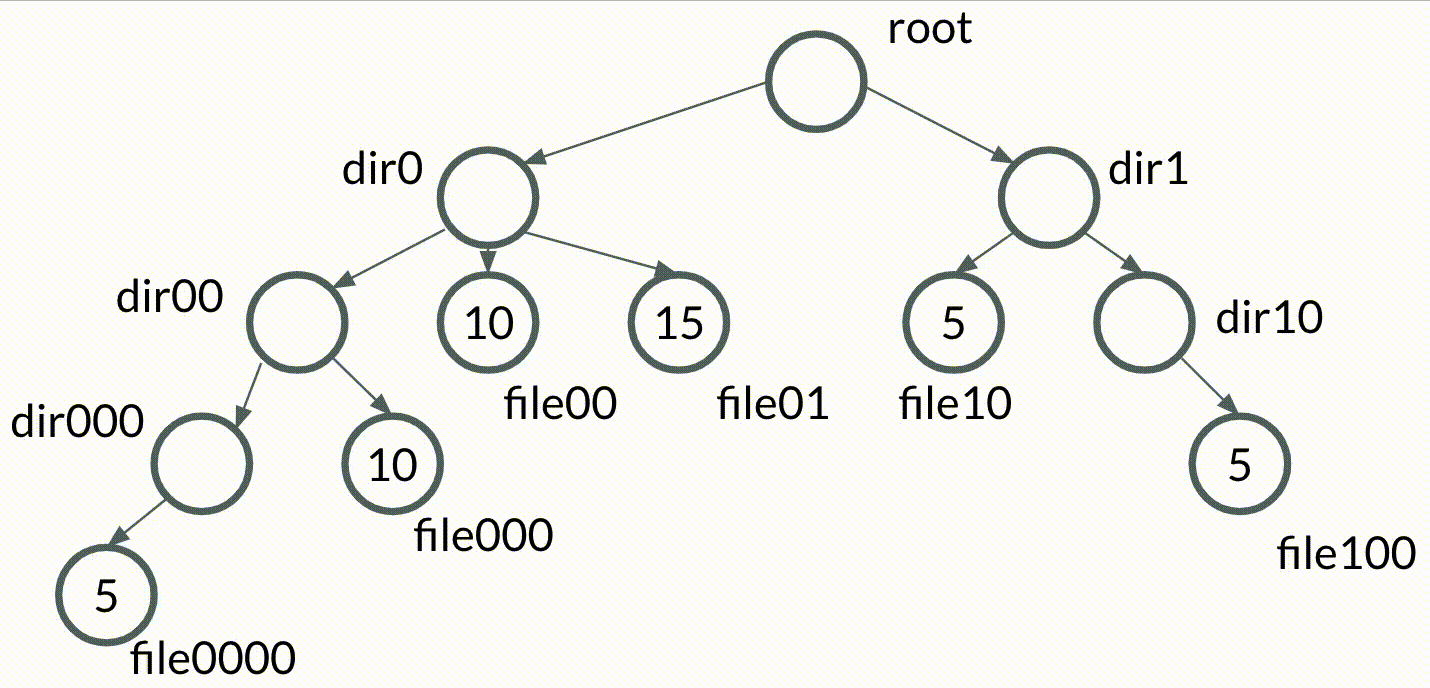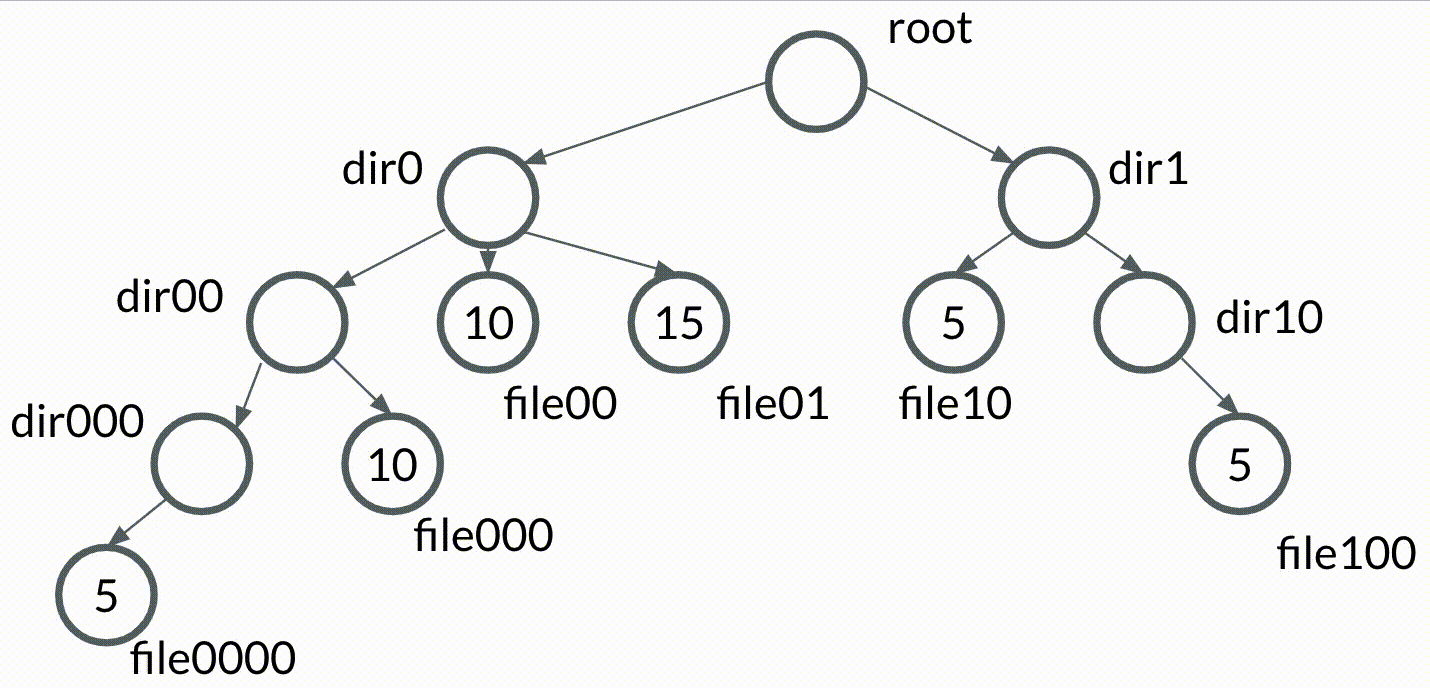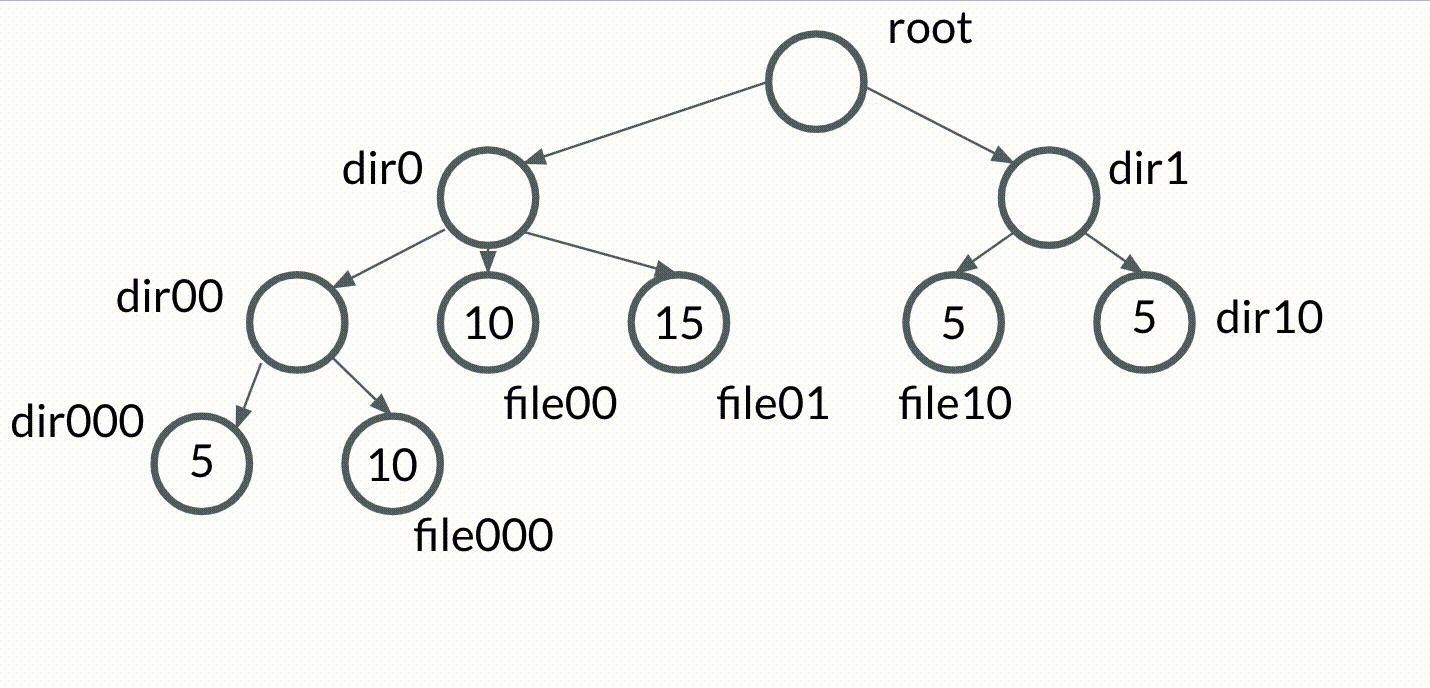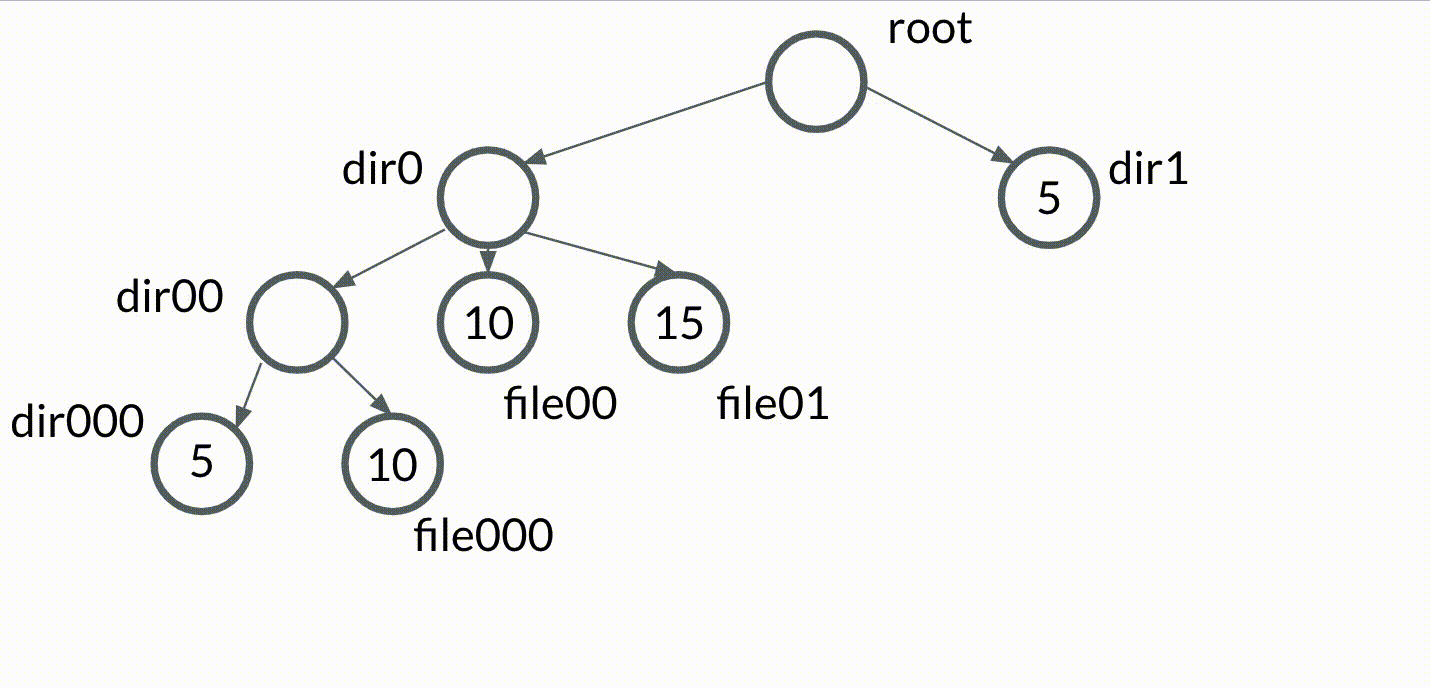
Planting our bubble tree
Let's get to implementing our bubble tree in Python. First, let's define a new class for a node in the bubble tree.
class BubbleTreeNode: '''Tree that 'bubbles up' common values from subtrees''' def __init__(self, path, value=None): self.path = path self.value = value self.children = []
Each node in a bubble tree with have a path (e.g. /dir/file.txt), a value (e.g. 5), and a list of its children nodes.
Next, we'll need to implement three different functions for our bubble tree. All of the following will be implemented as class methods so they have access to the current BubbleTreeNode.
insert()for inserting into a bubble treebubble()to bubble up identical leaf nodesflatten()to convert the bubble tree to a flat dictionary of key-value pairs
Wait just a second!
Wondering how we can print a complex bubble tree in a nice way? Check out my blog post for building pretty trees on the command line, which lifts code directly out of the bubble tree source in my algos project.
Let's start with insert(), which is the most complicated. Inserting into a bubble tree is almost identical to inserting into a trie.
def insert(self, path, value=None): '''Provide a full path to be inserted''' items = path.strip('/').split('/') assert items[0] == self.path, 'Invalid insert path in tree' self.insert_at_path(items[-1], items[:-1], value) def insert_at_path(self, path, tree_path, value): '''Insert new value at a specific path''' self.__insert_at_path(self, path, tree_path, value) def __insert_at_path(self, treenode, path, tree_path, value): if len(tree_path) == 1: if treenode.path == tree_path[0]: treenode.children.append(BubbleTreeNode(path, value=value)) else: raise ValueError('Invalid insert path in tree') else: if len(tree_path) > 1: try: index = next(i for i, child in enumerate(treenode.children) if child.path == tree_path[1]) self.__insert_at_path(treenode.children[index], path, tree_path[1:], value) except StopIteration: treenode.children.append(BubbleTreeNode(tree_path[1])) self.__insert_at_path(treenode.children[-1], path, tree_path[1:], value) else: raise ValueError('Invalid insert path in tree')
Next, let's implement bubble(), so our leaf nodes can bubble up to their parent.
def bubble(self): '''Bubble up values in the tree and prune congruent subtrees''' self.__bubble(self) def __bubble(self, treenode): if not treenode.children: return for child in treenode.children: self.__bubble(child) if all(child.value == treenode.children[0].value for children in treenode.children): treenode.value = treenode.children[0].value treenode.children = []
Finally, let's implement flatten(). This will allow us to convert the bubble tree to a dictionary of key-value pairs for easier parsing.
def flatten(self): '''Flatten the tree into key-value pairs''' return self.__flatten(self, '', {}) def __flatten(self, treenode, prefix, result): if treenode.value: result['/'.join([prefix, treenode.path])] = treenode.value else: for child in treenode.children: result = self.__flatten(child, '/'.join([prefix, treenode.path]), result) return result
Great! Now we can create a bubble tree with the BubbleTreeNode class.
>>> bt = BubbleTreeNode('root')
Insert some data.
>>> bt.insert('/root/dir0/dir00/file000.txt', value=10) >>> bt.insert('/root/dir0/file00.txt', value=10) >>> bt.insert('/root/dir1/file10.txt', value=5) >>> bt.insert('/root/dir2/file20.txt', value=10) >>> bt.insert('/root/dir2/file21.txt', value=15) >>> bt.insert('/root/dir3/dir30/file300.txt', value=15) >>> bt.insert('/root/dir3/file30.txt', value=10)
Bubble up common values to prune the bubble tree.
>>> print(bt) └── root ├── dir0 | ├── dir00 | | └── file000.txt (10) | └── file00.txt (10) ├── dir1 | └── file10.txt (5) ├── dir2 | ├── file20.txt (10) | └── file21.txt (15) └── dir3 ├── dir30 | └── file300.txt (15) └── file30.txt (10) >>> bt.bubble() >>> print(bt) └── root ├── dir0 (10) ├── dir1 (5) ├── dir2 | ├── file20.txt (10) | └── file21.txt (15) └── dir3 ├── dir30 (15) └── file30.txt (10)
And finally, flatten the bubble tree.
>>> bt.flatten() { '/root/dir0': 10, '/root/dir1': 5, '/root/dir2/file20.txt': 10, '/root/dir2/file21.txt': 15, '/root/dir3/dir30': 15, '/root/dir3/file30.txt': 10 }
Adding AWS infrastructure
Now that we have a working bubble tree, let’s consider how we’re going to deploy it to serve our notifications. We'll need some infrastructure to accomplish the following.
- A way to query an S3 bucket on a regular basis.
- A way to aggregate expiry dates into a minimal number of notifications (via a bubble tree).
- A way to actually send the notifications.
Rather than actually implement this infrastructure, I'm just going to model it out. Implementing this infrastructure extends beyond the scope of a single blog post, but I still wanted to touch on how to accomplish it. Here's a brief interactive animation to showcase how to build everything in AWS.

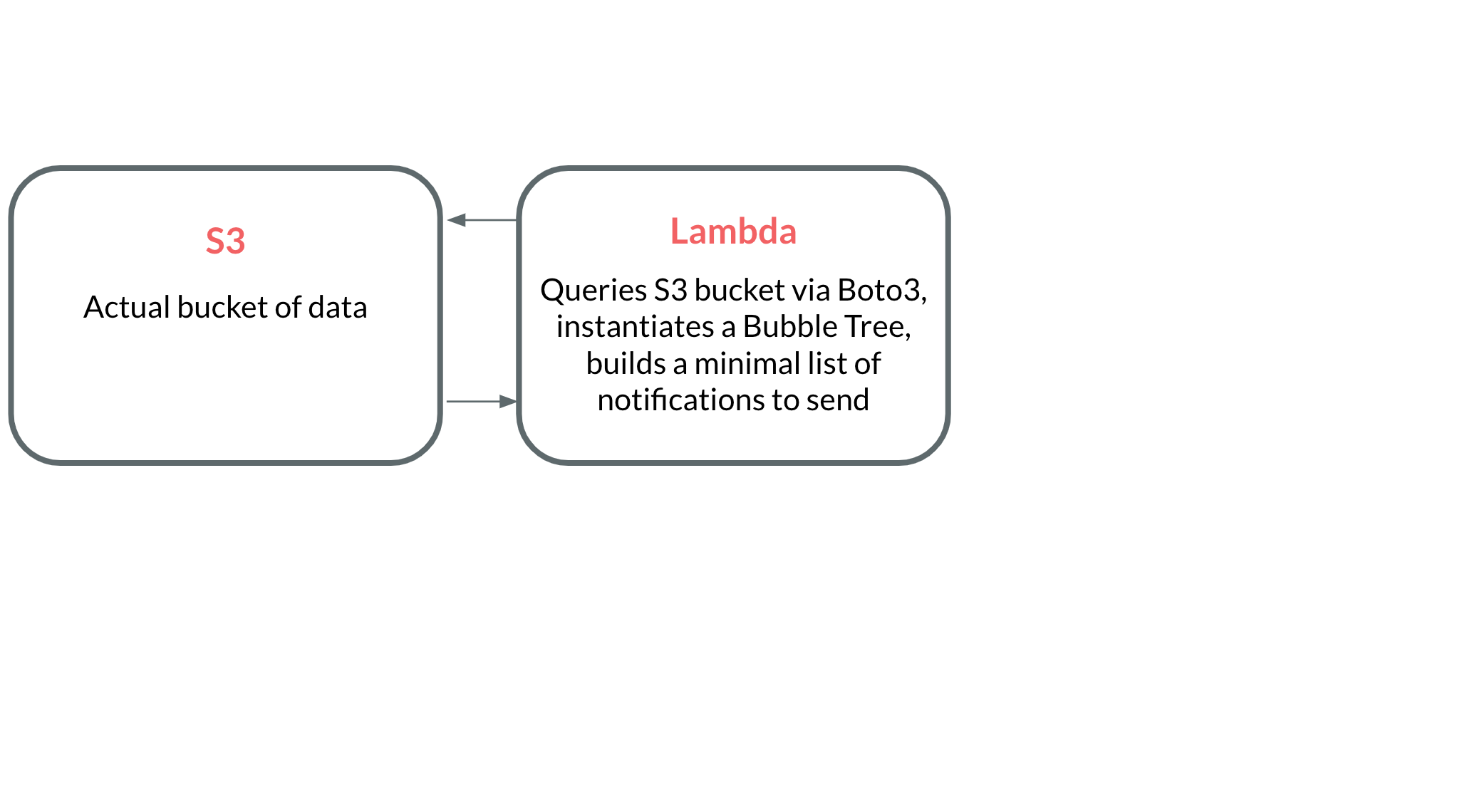
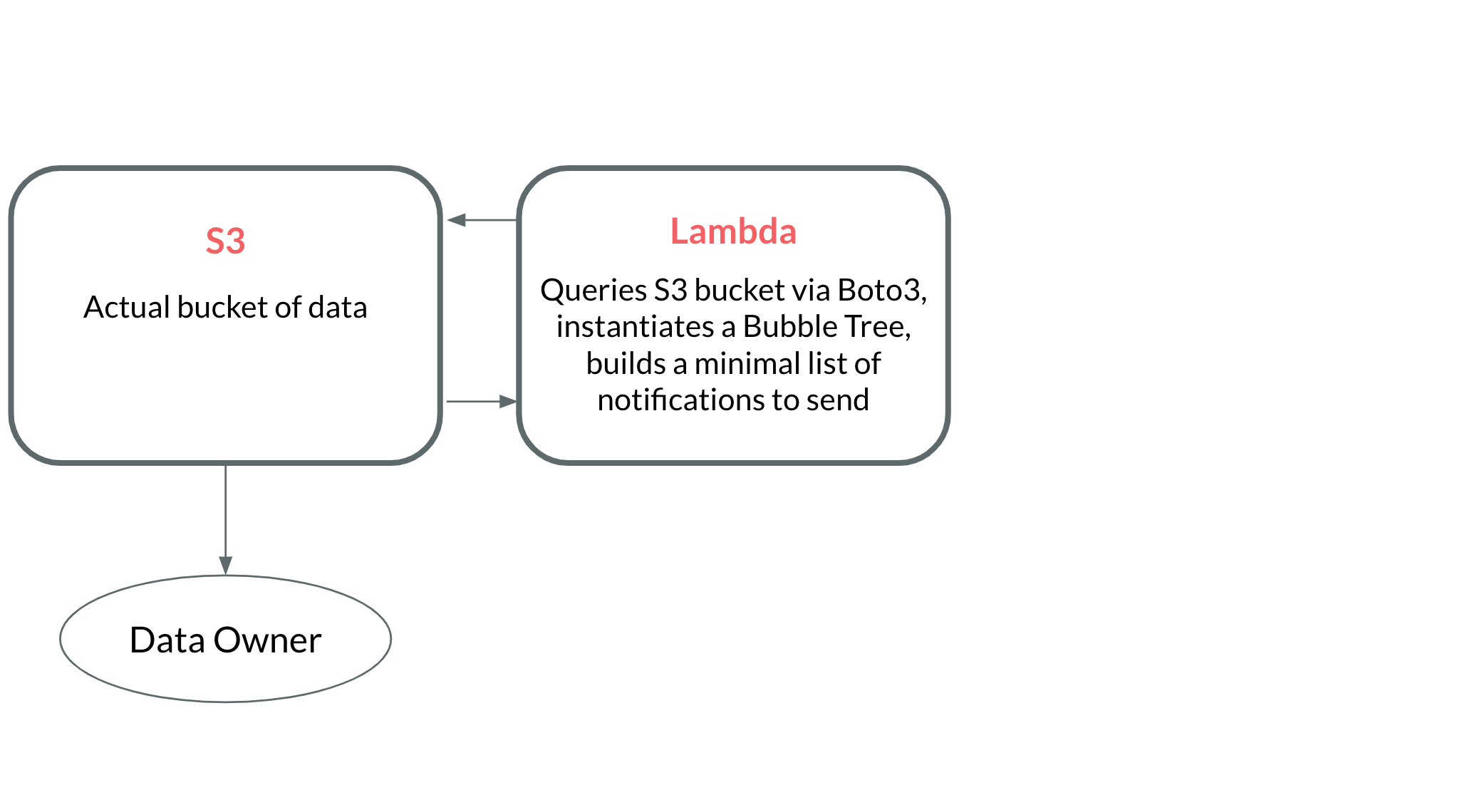
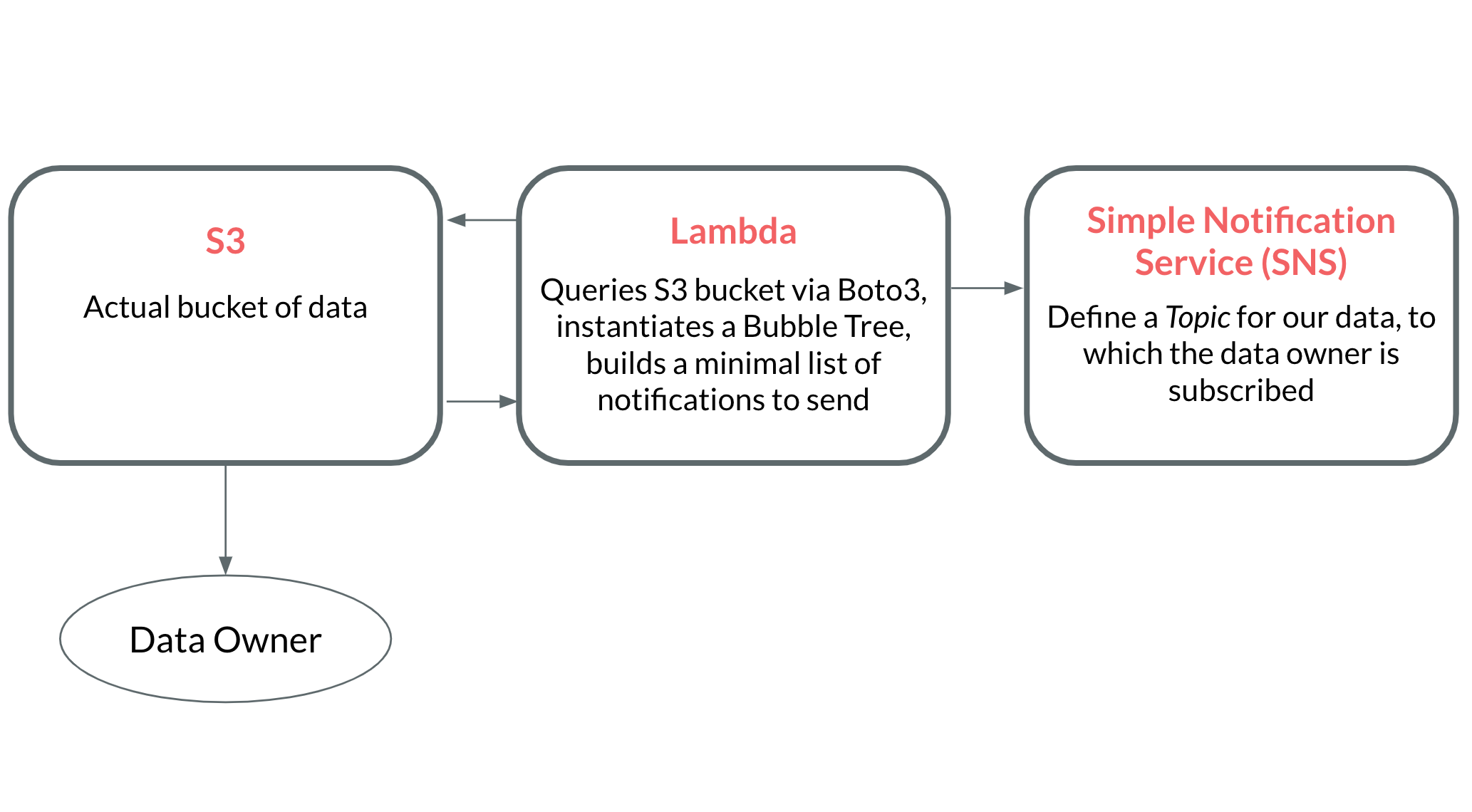
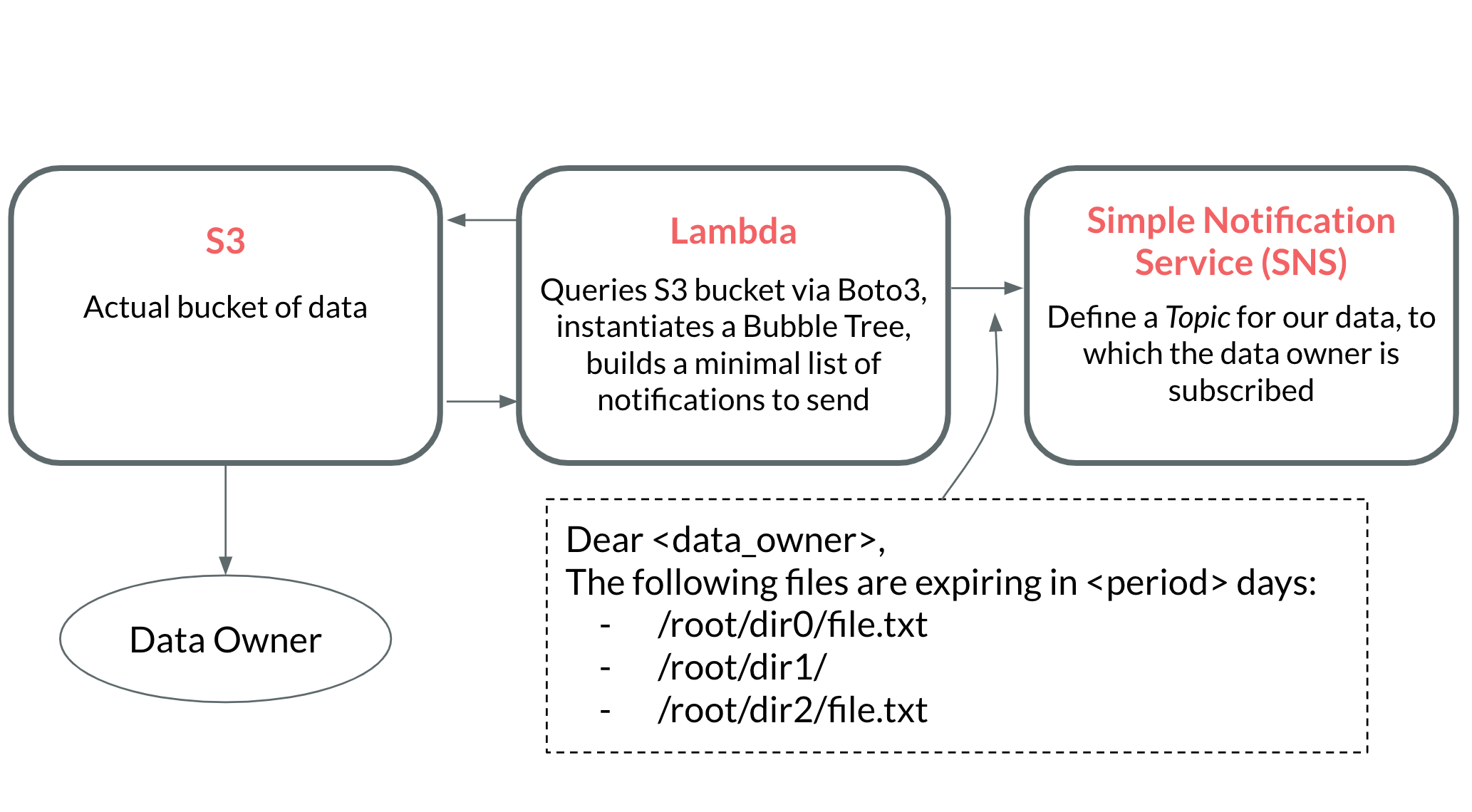
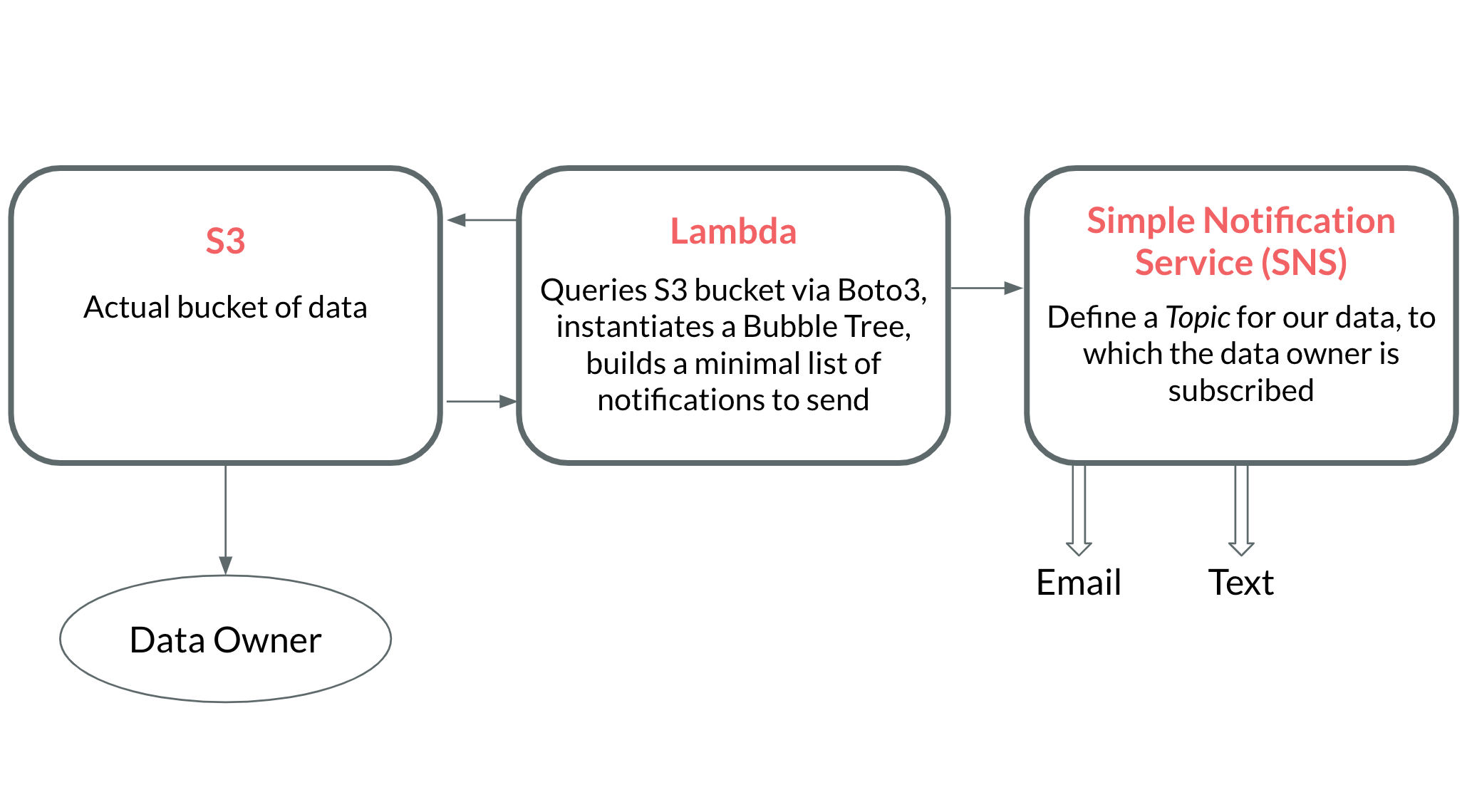
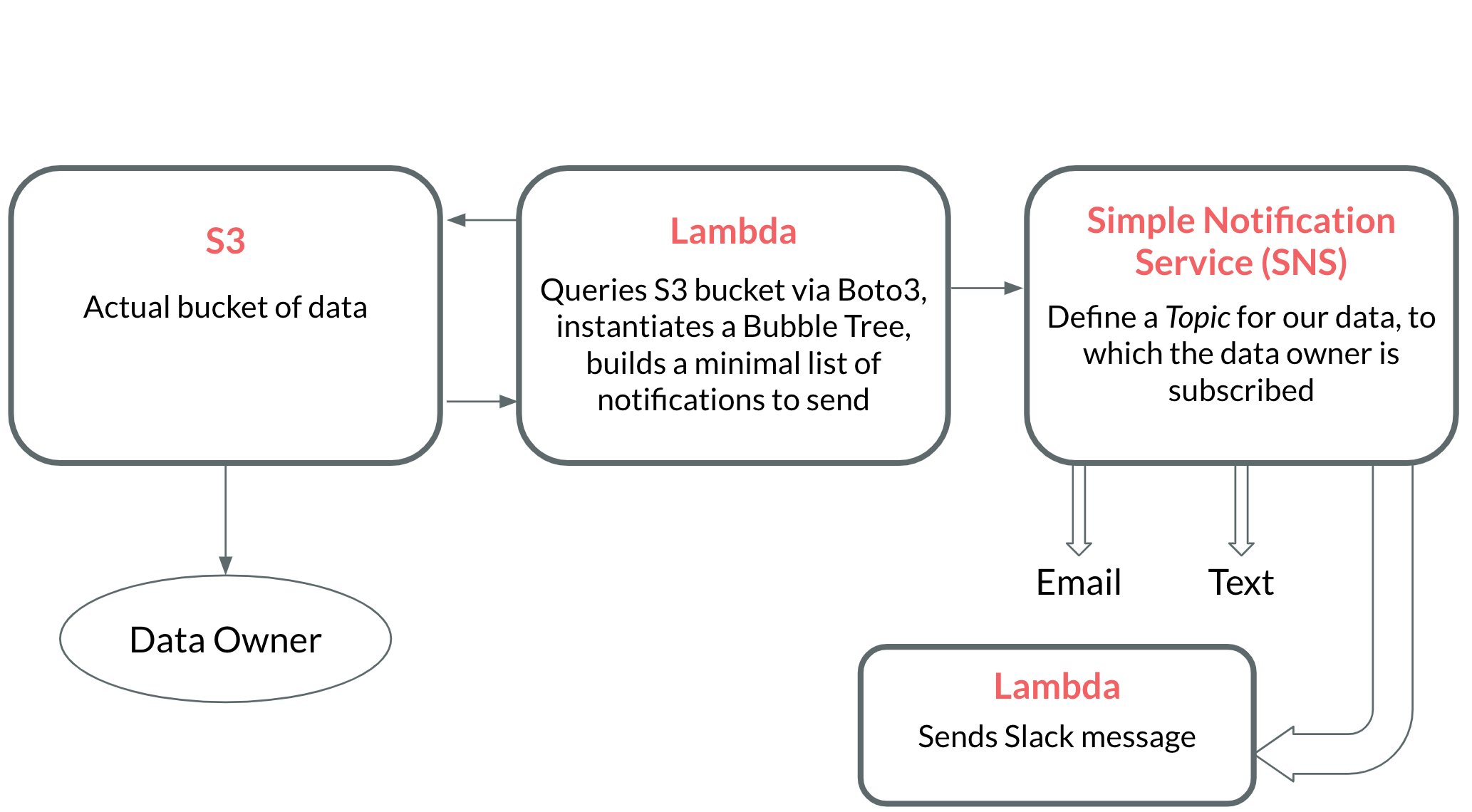
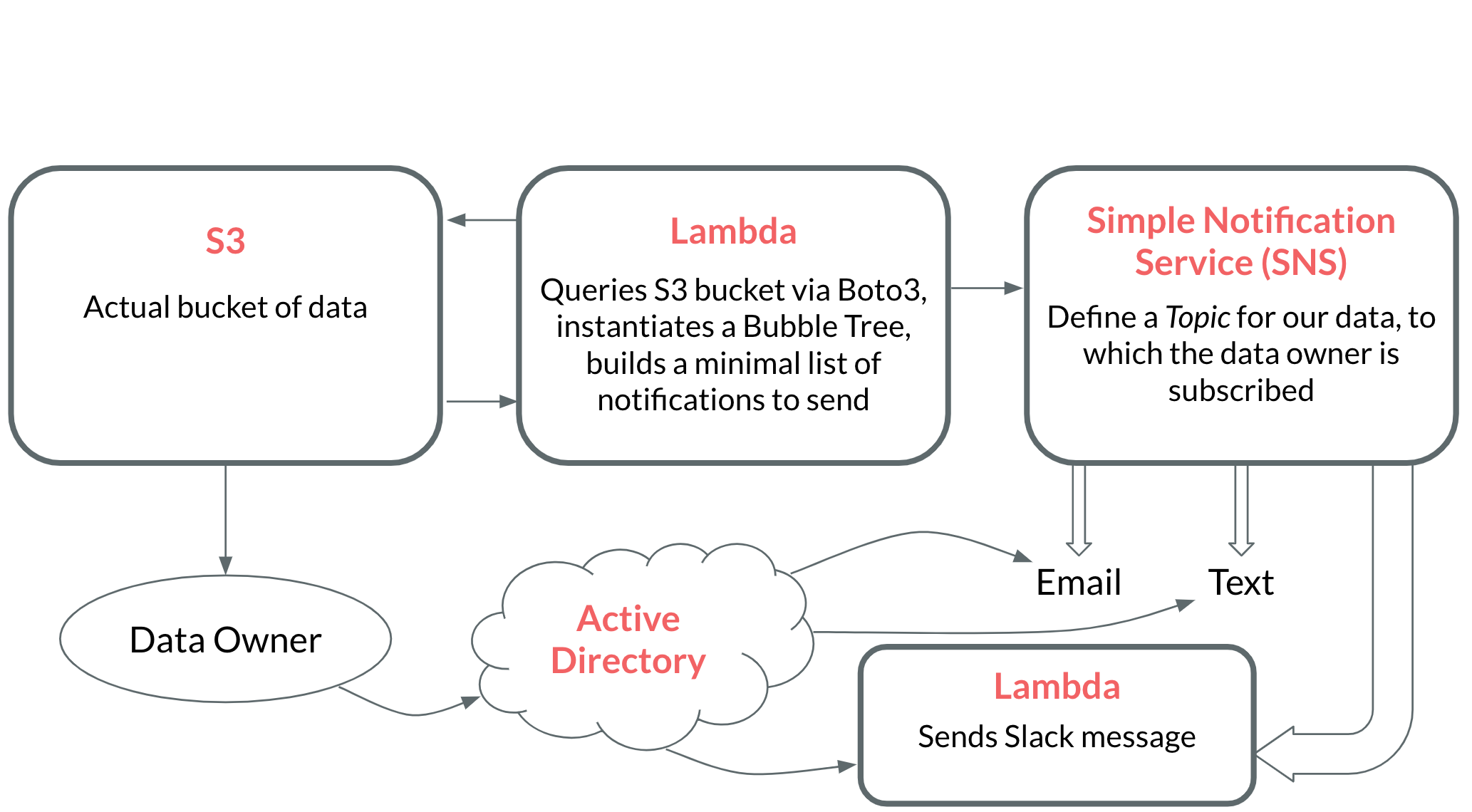
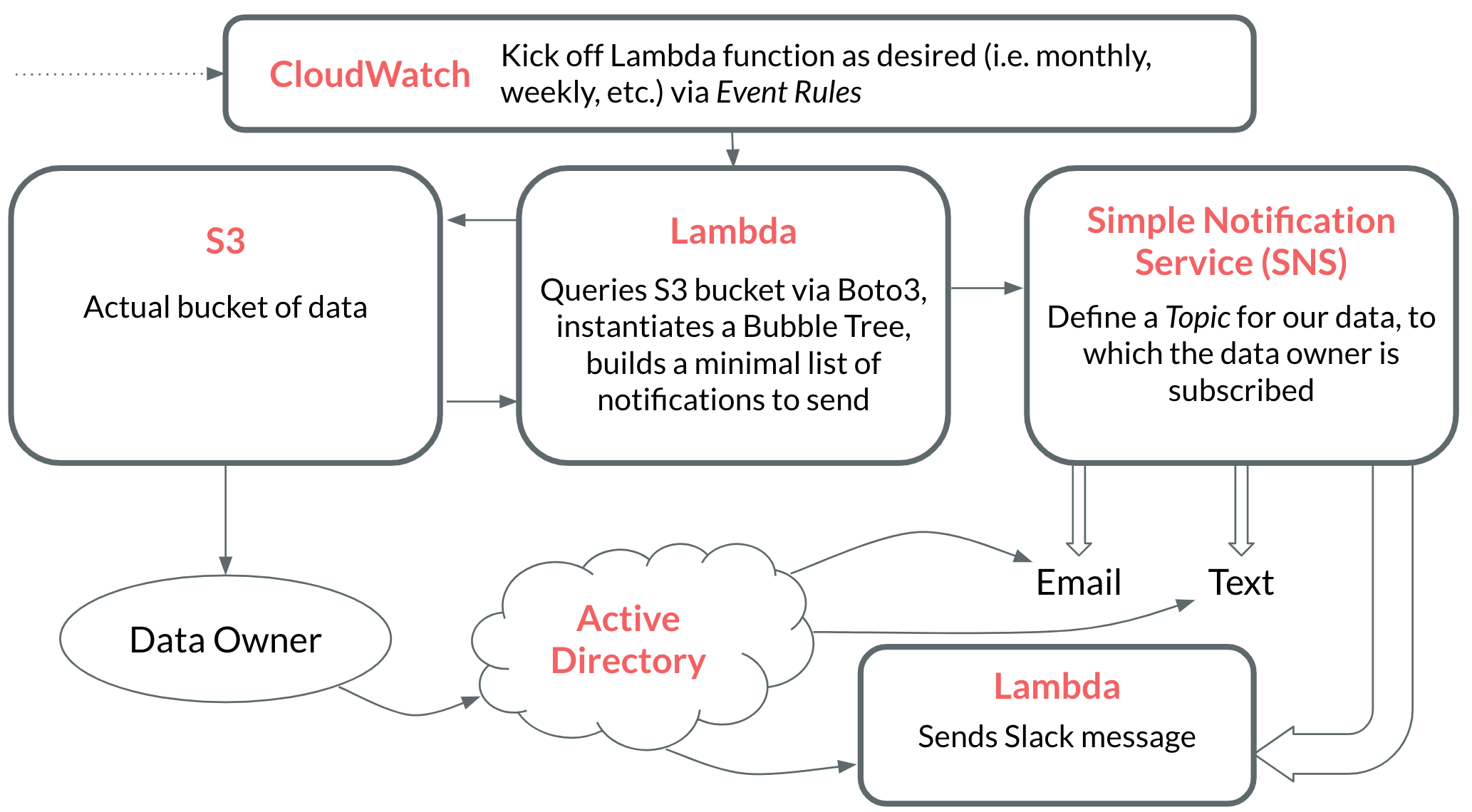
A look at the cost
Now for the moment we've all been waiting for...did this effort save us any money? Let's assume for simplicity that we have an S3 bucket with one million objects total that we'd like to send expiry warnings for. Let's calculate our cost per execution based on what AWS services we used (this is using the pricing example found under the S3 Object Lambda tab on the AWS S3 Pricing page).
| AWS Service | Estimated Usage | Estimated Cost |
|---|---|---|
| Lambda | 2 simple functions | Free Tier |
| SNS | Just a few messages | Free Tier |
| CloudWatch | Kick off monthly workflow | Free Tier |
| S3 | ~1 million objects, each accessed twice | ~$20 |
Great! We've worked out a solution that, other than engineering hours, only costs us $20/execution to run. To put that $20 in context, imagine that we could save up to $1000/month by sending out expiry notifications on a monthly basis (this is not an unrealistic example). It is an great trade-off to pay $20/month for a chance to save $1000/month. That comes out to $1040/year for weekly expiry notifications, $240/year for monthly expiry notifications, and $80/year for quarterly expiry notifications.
Pretty affordable. Can we make it even less expensive?
The current pricing model is greedy because it assumes that you must send two AWS S3 API requests per object in the bucket. If we could reduce the number of API requests per bucket-object, we would dramatically lower our overall cost. Instead of using GetObjectRetention for each object in the bucket, we could use ListObjectsV2, which returns metadata for up to 1000 objects in a bucket. If we assume the rough price model of $10 per one million S3 API requests from above, we would only need to send 1000 requests for a bucket of one million objects, instead of two million requests. This results in a new cost of 1¢ per execution, a cost reduction of 2000%! If it only costs 1¢ to run this solution, we could run it every day! Keep in mind that these numbers are all estimations; the actual cost could vary wildly based on your infrastructure implementation.
Conclusion
The bubble tree data structure is very powerful. This has been just one cool use case for it, but a "simplifiable trie," which is essentially what a BubbleTrie is, has plently of applications. I'll leave the next killer bubble tree app to you, my dear reader.
If you'd like to take a look at bubble tree's code, check out my project algos, which has a bunch of standard and novel algorithms and data structure implementations in Python. You can also read bubble tree's source code, which contains other tree structures as well. If this is your first exposure to AWS, or you're looking to dive deeper, a great place to start is AWS's tutorials, where you can pick interactive tutorials based on what kind of developer you are (embedded, back-end, etc). Even though AWS was the pioneer of S3, nearly every other IaaS provider has a similar product, many of which work with AWS S3's API.
Now go, prune the world's trees of duplicate data.
🦉
Artwork by pronoia
